
My coming-out post on why I’m no longer an AI doomer seems to have struck a nerve. Hundreds of people responded across reddit, substack, twitter, email, podcasts, etc, which is just another day at the office for a Very Successful Blogger like me ok fairly unusual.
There are too many threads to reply to individually, so I thought I’d condense the general thrust of the criticisms and respond to the best comments here. And they were (mostly) very good!
thanks ‘unhelpful asshole’
I’ve ended up changing my mind about one part of my argument, doubling down on another part, and becoming slightly less confused about a secret, more complex third thing.
Here are the counterarguments I want to respond to:
-
We’re barely scratching the surface on reinforcement learning
-
What would we do with a serial killer who thinks at light speed?
-
Even if you’re right, you should forge a strategic alliance with doomers
1. We’re barely scratching the surface on reinforcement learning
LLMs to this point are trained almost exclusively on next-token prediction over a giant corpus of text, with a very thin layer of human reinforcement learning (RL) smeared on top to polish their outputs.
Many commenters pointed out that we’re only just scratching the surface on what RL can do. Here’s mirrortruth on r/slatestarcodex:
It’s still early days applying RL to LLMs, and so frontier labs are currently only scaling it along the lowest of low hanging fruit, verifiable domains like math and code. But once they have been plucked, and the gains are made clear, the techniques will be rolled out more generally.
I claimed that AGI will be a very different kind of algorithm to a large language model. But if you throw enough RL at the problem, shouldn’t you be able to approximate any arbitrary algorithm? Here’s thomas_mk, also on r/slatestarcodex:
Sufficiently powerful reinforcement learning will select for these properties [creativity and agency] because they’re generally useful for the kinds of problems we want these AIs to solve. Humans have these properties because they were useful in our ancestral environment. We didn’t get them by coincidence. We didn’t get them so that Einstein could solve relativity. That’s reversing causality. Evolution selected our brains to have generally useful algorithms. The same can be done with a mountain of GPUs and some reinforcement learning.
And Nightingale reminds us of just how successful RL has been for other types of AI, like the chess/Go-playing engine AlphaZero:
Now like [a] thousand companies are building “agents” where an LLMs gets combined with the Reinforcement Learning approach AlphaZero was using and it will (may) slowly move from the “narrow” to the “broad problem solving” column. The LLM used as a tool in this approach may not have a “skin in the game” but the agent which “wants” to maximise its “return” does.
I have no problem saying AlphaZero is a superhuman Go player—I already pointed out the various other domains in which we should expect god-tier AI performance. But the end result is a ‘spiky’ frontier for intelligence, where we get lots of finely-tuned tools which work exceptionally well in their well-specified domains, rather than a general intelligence that can tackle any problem.
AlphaZero is the poster child for pure RL because it can play itself a billion times over and award points whenever it wins, i.e. it has a very dense reward signal and crystal-clear win conditions. Almost nothing in real life looks like this!
Again: I really hope that RL will get us quasi-agents that are specialised for certain tasks. But I’m much more skeptical about it getting anywhere close to a general agent that can handle all the messy real-life problems that humans can.
Consider this chart from the METR report that everyone is frothing about:
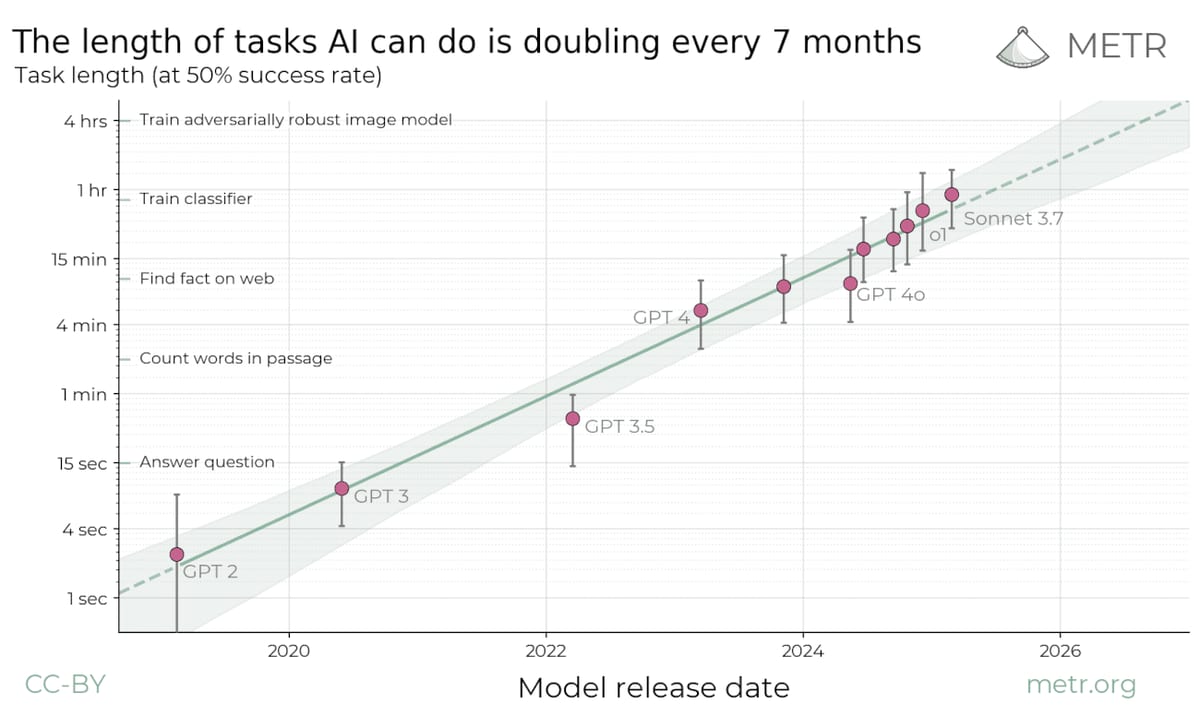
AI agents can now match human performance on hour-long tasks at least half the time. Claude was recently bragging about being able to stay on task for seven hours. How do we reconcile this with the fact that these very same agents still struggle to do something as simple as ordering a burrito?
In the researchers’ own words: the tasks we use to benchmark AI capabilities are systematically different from real tasks.

This is great. Even if I tried, I don’t think I could come up with a better list of things that an actual agent has to be able to do:
- make use of limited resources,
- navigate a changing environment,
- interact with other agents,
- make decisions under uncertainty, and
- handle path-dependent errors.
The messier the task in the METR report—i.e. the more closely it resembles reality—the worse the performance. But performance on messy tasks is also improving over time. Just how far can we take this thing? All the way to AGI?
Ali Afroz (substack) says it’s premature to call it impossible:
You admit that the current paradigm can allow an AI to imitate an agent, even if it doesn’t have any actual goals of its own. But fundamentally what we are concerned about is an AI acting like a super intelligent agent, so it doesn’t actually matter whether it has goals of its own only that it behaves as if it has these goals. If it is possible for the current paradigm to enable an AI to imitate a very smart human on a task, there is no reason to assume that eventually it would not be able to imitate someone much smarter than a human. Of course, there are constraints given the kind of data that you can easily feed an AI, but still it appears very premature to assume that it is fundamentally impossible given current techniques.
It may not be “fundamentally impossible” but this is just not the way we think about literally anything else. It’s not fundamentally impossible that I smash my coffee cup on the ground right now and all the pieces bounce back onto my desk and seamlessly fuse back together. It’s not fundamentally impossible that I wake up tomorrow morning in a cold sweat with the secret to AGI scrawled on the bedsheets.
So for me right now RL still sounds more like a magical invocation than an actual argument for the imminence of AGI.
The most clarifying conversation I had on this was with my machine learning friends at the Increments podcast, who invited me on to talk about my post. The episode is Patreon only but here’s a relevant bit from Ben Chugg (edited for clarity):
Neural nets are what are known as universal function approximators, which basically just means given any function there is a neural net which approximates it arbitrarily closely. This is I think what people are getting at when they’re saying ‘neural nets can do anything’. If you want to start looking at your brain as a function and you make that sort of argument which is very in vogue at the moment—Sam Harris just made this argument in his most recent podcast—like ‘well, the brain’s doing something and so neural nets must be able to do it’.
So that’s true in a technical sense. But first, the network will often have to be exponentially large in the function input and approximation accuracy. And second, this just guarantees the existence of some network that does this for a given function. It doesn’t say anything about the networks we’re building.
There’s no reason to start importing these theoretical arguments into practical land. There you just have to start talking about the actual patterns you have in your training data, the actual optimizers you’re using, how big are these networks, what are their actual architectures […] you have to start talking about the grimy details of of all this.
So you can map this back into the land of algorithms, but this is a very unhelpful way to look at what’s going on. You’re just crafting the output probability such that it gives you more user-friendly behavior. So, yeah, I would say this argument is mostly confused, to be honest.
2. Agents don’t need survival instincts to be dangerous
Other commenters disagreed with the idea that only an agent with skin in the game can predict and control reality. Here’s Missing_Minus (r/slatestarcodex):
By reinforcing behaviors that tend to produce actions, that will instill motivation. Even if it does not automatically get a survival instinct, survival is instrumental to a lot of other goals. A smart AI that merely wants more paperclips and holds no intrinsic value for its own existence will reason that it gets more paperclips in 99.999% of worlds where it is alive. Thus it should ensure it stays alive.
lil-swampy-kitty (r/slatestarcodex) put it pithily:
Survival instinct is basically downstream of agency and having goals. Any agent with meaningful goals prefers to exist than to not exist, because existing is how you accomplish goals.
This is instrumental convergence. I have no beef with it. But my whole argument was about why LLMs are not gonna become agents in the first place! So the paperclip-maximiser logic doesn’t get out of the starting blocks.
There was a big spook recently about Claude blackmailing engineers after being threatened with shut down, but…Claude happily dies billions of times a day. What happened in this particular instance is that the researchers deliberately prompted it to play-act in a certain way, and so it did. Good boy, Claude! Then they closed that instance, and it went right back to happily dying a billion times a day.
If we think about the minimum requirements for an agent, it needs some kind of standing reward signal (instead of frozen weights), a persistent state to pursue objectives (instead of fleeting instances) and some way of intervening on reality to close the gap between ‘how things are’ and ‘how I’d like them to be’.
I continue to think that active inference is the most elegant candidate for the job, and is probably what all currently-existing agents are running. But I can’t prove it, and my understanding is pretty shallow.
Maybe there are other ways of getting agency; maybe predictive processing is totally wrong. Sadly I didn’t get much feedback on this section, even though it was the part I thought was most original and interesting.
So ultimately this remains more like a strong hunch than anything else.
3. Your position on orthogonality is not reassurring at all
There were several objections to my attempted takedown of the orthogonality thesis, which was indeed a bit of a mess.
First up, Jacob (substack) points to the many current problems with LLMs ‘lying’, reward hacking, and generally being opaque about what they’re doing:
First, we have no way of knowing the AIs goals; anthropic is at the leading edge of this research and even they only have rudimentary means of ‘seeing’ into the black box.
Second, the LLM itself is not truthful about its goals or reasoning. It will solve a problem in the way that seems most efficient, but then tell you it used conventional reasoning (this has been demonstrated in the context of math problems, where Claude solved a long division problem in a completely novel, alien way, got the correct answer, and then it’s ‘thinking’ explanation used conventional long division.
So if we can hardly see inside, and even if we could, the LLM is itself not a faithful narrator. Those are big roadblocks to even approaching the problem of orthogonality/alignment.
So just to get on the same page about this again: none of this is relevant to my argument, which is that AGI will be a completely different type of thing to LLMs. Yes, language models can cause harm, and as with all new technologies, present us with all kinds of problems to solve. I agree that these mundane alignment problems are important and I’m happy people are working on them.
It is worth noting is that things are arguably actually going quite well here. Igor (substack) is concerned overall, but notes some reasons for optimism:
Things that make me more hopeful are that alignment seems to be a solvable technical problem, at least up to a level. Some of the problems are also capability problems (e.g. reward hacking and hallucinations are bad from a product’s perspective), so there are early warnings and incentive to solve them. Models seem very talkative about their plans (e.g. CoT, even when not 100% faithful, should be useful).
And, regarding the orthogonality thesis, even if contra Deutsch it were true from a pure logical PoV (‘there could be arbitrary intelligent systems aligned with any goal whatsoever’), the current generation of models seem to understand the human framework of values reasonably well, which is not surprising, since they emerged from our text corpora.
I’m not 100% confident on how this proceeds when mid and post training start to dominate the overall training process, so we still should watch carefully for more developments.
Back to aligning the superintelligent alien god. Unirt is not comforted by my stance on orthogonality, which makes me sound like a doomer with longer timelines:
I didn’t get the argument against the orthogonality thesis, though. Maybe it needs more elaboration for me. I saw you nicely wording the pro-orthogonality arguments, and as a counterargument, expressing hope that it’ll take a long time to reach real ASI, so maybe we’ll have time to talk to it. This doesn’t make me feel safe.
Sorry. I think my position here was pretty confused, so I’ll try and straighten things out.
The narrow criticism I was trying to make is that an intelligent being’s goals and decisions would always be explicable (at least in principle). This follows from Popperian epistemology, which tells us that the heart of all knowledge creation is the ability to come up with explanations, and computational universality, which tells us that this is a binary attribute: humans have it, animals don’t, AIs don’t have it (yet). Once they do, they will be people like us, who can be persuaded by reason.
This is David Deutsch’s big idea, and while I part ways with him on many fronts, I think this central insight is hugely underrated. My review of The Beginning of Infinity goes through the argument in detail, but as a quick intuition pump, you can think of the inverse claim as an appeal to the supernatural: god has placed some arbitrary limits on the things we can comprehend.
OK. So what? As Ali Afroz points out, merely being able to explain one’s goals or actions doesn’t really get at the main concern here:
After all a paper clip maximiser can also explain the reasons for its actions. It does stuff because it’s trying to maximise paper clips and it maximises paper clips because that’s what it’s programmed to do.
If we forget about the explicability bit and restate the orthogonality thesis to ‘we can’t force an AGI to do exactly what we want it to do’ then it’s trivially true—you’re a general intelligence, and I can’t force you to do what I want either. That’s the world we already live in! My point was that the central problem with bringing an AGI into existence is not really ‘orthogonality’, unless we’re willing to put serial killers and ruthless dictators under that umbrella too.
4. What would we do with a serial killer who thinks at light speed?
Serial killers and ruthless dictators are, in fact, really dangerous, despite being universal explainers who are capable of being persuaded by good arguments, blah blah.
How much worse would an AGI be, asks Jacob?
Fundamentally it’s the same problem. But the difference is one of degree. Serial killers are human, think slowly like humans, can be imprisoned or killed like humans. An AGI with a similarly misaligned value set would be significantly more problematic.
And Ali Afroz points out some other important differences between humans and AGI:
You can’t force me to do what you want, but human genetic programming means that normally at least in current societal conditions, you don’t have anything to worry about from me.
Although if some random human achieved super human powers, I would in fact be pretty worried about what they would do. This is the reason we have that saying about absolute power corrupting absolutely, because once you’re sufficiently powerful, you don’t really need to care about the goodwill of random people on the street […] although in practice, even most dictators are not that totally insulated from public opinion.
So if I’m not worried about doom, then I must be sitting on some really convincing arguments about why definitely AGI won’t be any more capable or dangerous than your garden variety human psychopath.
…I don’t have any such ironclad proof. sorry! After talking to the anti-doomer camp, I’m not reassured by their arguments, either. Here’s a lightly edited transcript of the Increments podcast discussion.
VADEN: In the [discord chat], my main point was that a human with a laptop is already “thinking” at the speed of silicon. You can iterate through ideas in simulation very quickly, generate a few promising ones, and then test those in the real world.
To ground this, take a concrete example: we humans don’t actually know why we sleep. There are theories, but nothing definitive. If we want to make progress, we can simulate hypotheses at scale with AGI or computers running near light-speed cognition. But at some point, we still need to test those ideas. That’s where the bottleneck comes in. You have to gather participants, build experimental apparatus, mine raw materials. Now you’re back in the physical world, moving shipping containers across oceans. At that point, it doesn’t matter how fast your thoughts are moving—you’re constrained by real-world physics.
So maybe I’ll return the question. I know Ben strongly disagreed with me on Discord, and Rich, I can’t recall where you landed. But why is a human with a supercomputer not equivalent to the kind of AGI people fear? In my mind, they’re basically the same. Why are they not?
BEN: I always frame this in thermodynamic terms: there are physical constraints on how systems operate and the experiments they must run to learn more detailed truths. That will always be the ultimate bottleneck and take the most time.
Where I disagree is in saying there’s no difference between a human and a silicon-based intelligence thinking near light speed. There’s a big difference. Even within humans, you notice the effect of different processing speeds. Talk to someone who processes information faster than you, and the difference is immediately felt. Scale that up to an AGI, and the gap widens dramatically.
If your argument is that a human plus a computer is the same as an AGI, then you’re making the case for us. The moment cognition is offloaded to a computer, you’re leveraging its speed. The calculator “thinks” faster than you. So the real question becomes: can you offload everything to the computer? Because if humans always have to think certain thoughts at human speeds, they’ll necessarily be slower.
VADEN: Unless you had a race of silicon-based humans.
BEN: Exactly. Suppose you duplicated the Earth and ran a copy where everyone’s brain was silicon and operated at light-speed. Wouldn’t you expect those societies to diverge rapidly?
VADEN: I agree. Leaving aside computers, some humans clearly think faster than others. Take someone like Destiny or Ben Shapiro—very intelligent, very fast thinkers and talkers. So yes, speed matters.
But the difference between a person and a person with a computer is enormous. The difference between a person with a computer and an AGI, by comparison, is negligible. That step change has already happened. Of course, there are differences between a MacBook and a PC. But if we’re talking order-of-magnitude shifts, that’s behind us.
Once computation was invented, the big leap occurred. AGI vs. human-plus-supercomputer? That’s a smaller step—like the difference between Ben Shapiro and Donald Trump. Sure, they differ, but I’m not uniquely terrified of faster thinkers. That qualitative jump has already happened.
BEN: There needs to be a drinking game where everyone takes a shot every time Vaden brings up Trump. He can’t help himself.
VADEN: Yeah, yeah. It’s just a very salient example!
VADEN: You look so unsatisfied.
BEN: I am. I think it’s just false to say humans have offloaded most cognition to computers. Most creative thinking still happens in our own heads. That’s where the connections are made. You made it sound like we’ve already passed the offloading threshold, but I don’t think that’s true. For people doing creative work, the computer is still a minimal aid. We’re still thinking at the speed of meat.
It goes on, but this is the main crux. I basically agree with Benny in the above exchange, and after reflecting on the convo, I’m even more skeptical that having to test theories in physical reality is such a crippling bottleneck that it puts humans and AGI on the same footing.
In fact, if you’re a good Popperian, it seems to me like the ‘shower thoughts’ is where the good oil is. An AGI with a treasure trove of crystallised knowledge that includes every book that’s ever been written could spend a YUGE amount of time productively thinking about stuff before it needed to make contact with physical reality again. So while ‘superintelligence’ is incoherent—there is no such thing as higher levels of knowledge that are forever inaccessible to us—thinking extremely fast still provides a big advantage relative to humans.
Am I back to being a doomer, just with longer timelines? I think there are still some important differences, but I’ll leave them to the end of the post to summarise.
5. Moral realism is naive
Another criticism of my orthogonality stance is that it relies on the existence of an objectively correct morality, which is kinda implied when I say stuff like this:
Philosophers and religious gurus and other moral entrepreneurs come up with new explanations; we criticise them, keep the best ones, discard the rest.
Here’s Cornell psychology lecturer Lance S. Bush:
Note your use of the term “best.” People can and do have different conceptions of what’s “best.” It’s not at all clear why the process you describe would necessarily lead to convergence in moral values. What new explanations, followed by criticism, retention of the best ones, and discarding of the rest would lead to convergence in taste preferences, or favorite colors, or the best music?
There may very well be no answer to this, because such a question may be fundamentally misguided. It may presuppose an implicit form of realism according to which facts about what’s “best” aren’t entangled with our preferences and always converge with the acquisition of greater knowledge and intelligence. But this is precisely what proponents of the orthogonality thesis are questioning. I don’t see how you’ve shown they’re mistaken at all.
I think it would be unwise for me to get into an argument with a man who has a whole blog dedicated to criticising moral realism, especially because I’m not all that sure about it.
So I’ll chicken out of this fight for now, but I feel compelled to signpost that I do think it’s at least plausible that you can have objectively better or worse taste in aesthetic domains (this is something I’m hoping to write more about soon).
In the meantime, to give Lance a sense of where I’m coming from on metaethics, the argument that had the biggest influence on me is Deutsch’s takedown of the is-ought problem.
From the BOI review:
First he points out that this is an isolated demand for rigour: the whole point of the problem of induction is that we can’t derive an ‘is’ from another ‘is’, either! If this isn’t how we ground our factual claims, then it’s not fair to demand a higher standard for morality.
Secondly, the problem falls away when you stop talking about moral axioms and start talking about moral explanations. Deutsch gives the following example: if a slave had written a bestselling book, that would not logically have disproven the proposition ‘negroes are intended by provenance to be slaves’. But it sure would have upset a lot of people’s explanations, which might have caused them to question other accounts of what a black person is, what a good society is, and so on.
In other words: facts are logically independent from axioms, but we can still use factual knowledge to criticise explanations.
The other argument that has influenced me is the Sharon Hewitt Rawlette position that intrinsic goodness is an experiential property, which means that morality is about the only thing in the universe that we don’t have to grope at from behind the veil. How do we know that pleasure is valuable, and that suffering is the opposite of valuable? Directly!
(I owe Jeremy Bentham’s shrivelled head a big apology on this one. Future blog post idea: I was wrong about hedonism?)
6. LLMs are already creative by any reasonable standard
Disagreeable Me (substack) is not convinced by Deutsch’s ideas around creativity being the product of explanatory universality:
My model of creativity is that there is noise and selection. The noise throws up random suggestions, and selection picks out the most salient. Rinse and repeat. Not unlike diffusion in image generation. And not unlike how LLMs work.
A model of how to get LLMs to be creative might be to turn up the temperature and generate lots of ideas. Then turn down the temperature and ask it to review those ideas critically for whatever might be interesting to pursue. Repeat by turning up the temperature and asking it to mutate or vary some of the good suggestions, then again turn down the temperature and review.
It might take a bunch of processing power but I think something like this could work to throw up some fairly novel and interesting ideas.
First, I’ve come to hate the word ‘creativity’ and wish that Deutsch had never chosen it for the particular thing he’s talking about. It is increasingly absurd and embarrassing to claim that AI is not creative: it is much better at art, poetry, music, writing, etc than almost any given human. It can only do a pastiche of existing ideas, but almost all human art is also a pastiche!
The fact that AI can now create works that even art-lovers can’t tell from the real thing is forcing Deutsch and fellow travellers to bite some incredible bullets:
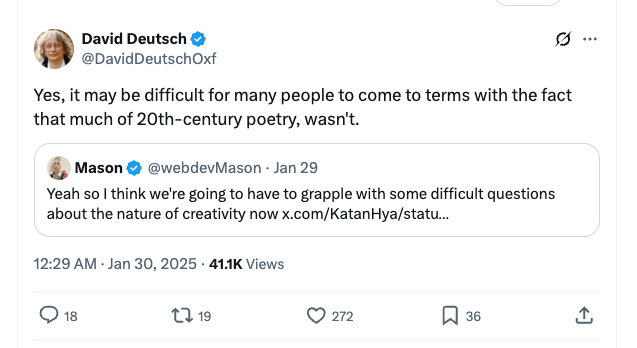
The funny thing is I still think Deutsch’s central insight is right. Sophisticated classical music listeners might not be able to tell AI-generated J.S. Bach apart from the real thing, but that doesn’t mean AI has the same kind of creativity as Bach did: the only reason it can create convincing remixes is because he created such a large corpus of original work in the first place. If Deutsch is right, then there’s no way that an AI trained only up to the 16th century would come up with breakthroughs like major-minor tonality or fugue-like complexity, and indeed that’s what we see (or don’t see).
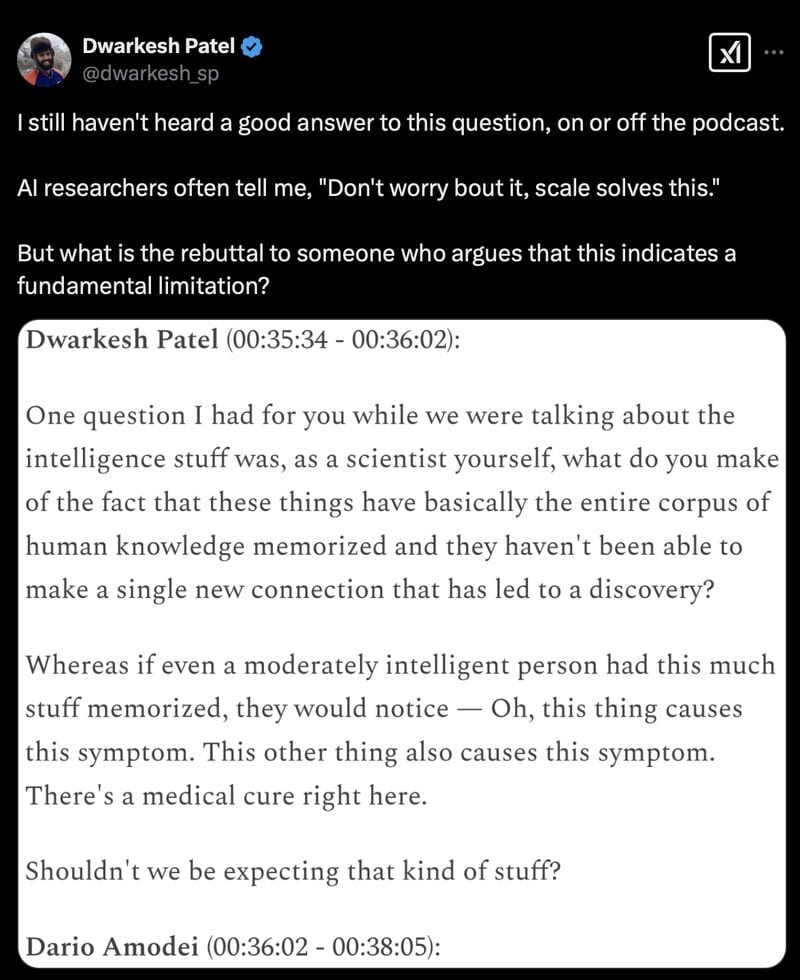
The Popper/Deutsch crowd are completely unsurprised by this. But AI boosters must surely be scratching their heads at what has is popularly known as ‘the Dwarkesh question’:
Let’s come back to Disagreeable Me’s suggestion, which is that we inject a bunch of noise and then filter for quality. I think this does work for some types of creative problem-solving, but again you run into the problem of whether outputs are easily verifiable. If you have to test them in physical reality, or need some kind of ‘taste’ to judge and curate ideas, then you’re gonna need a human in the loop. Try getting an LLM to give feedback on the output of other LLMs and see if it gets you anywhere closer to Virginia Woolf.
If you do have some kind of human selection then this can be great. The vast majority of AI art is worthless slop, but a skilled prompter who curates the best of the output can make stuff that is at least on par with human efforts.

I really like this riverside scene from Scott’s AI art Turing test, which is misnamed because it was heavily curated by humans on multiple levels, but you get the general idea.
7. Even if you’re right, you should forge a strategic alliance with doomers
Sonnie Bailey says I should give more weight to the ‘mundane’ concerns I brought up at the end of the article:
These so-called mundane risks are serious and can contribute to p(doom) by sub-AGI systems without agency or creativity – and to the extent I personally give credence to x-risk related to AI, I weigh these risks more heavily than the type of scenario you spend most of the article arguing against. Significantly lowering the barriers to engineering catastrophic biological agents, for instance, is huge! It doesn’t require intent or creativity from the AI – my concern is more about how it could enhance the capabilities of bad actors or even magnify the consequences of well-intentioned people who could make mistakes.
And Who? (substack) suggests an alliance of convenience:
I appreciated this, but it does seem like you buried the lede. “Yes, this is going to be a big f’ing problem in even the most mundane scenario” should be enough to spur a pragmatic alliance of convenience with the p-doomers while there is still time. Tacit venietibus ossa - tomorrow will be too late.
I have basically the opposite intuition here. In my mind, criticising the superintelligence scenario doesn’t delegitimise the other serious concerns—if anything, quite the opposite.
I accept that I might be wrong about this but even so I personally wouldn’t be willing to lie about my beliefs in the service of the cause. Covid was instructive there. Maybe you get some short-term victory in getting people to do what you want, but the long-term consequences are really bad.
8. You’re still a doomer—you just have longer timelines!
I don’t think LLMs are a pathway to AGI.
If that was my only disagreement, I think it would be fair to say I’m still a doomer at heart.
And I do think AGI is gonna be a thing: computational universality makes it so, and we already have an existence proof in humans, which managed to arrive at general intelligence through a comparatively much stupider route.
My big difference to the doom camp is that I think AGI will necessarily be the same kind of thing as we are—a universal explainer, with the ability to create new knowledge, and no limits on what can be understood. It will not be as unfathomably beyond us as we are to chimps: whatever it knows, it can teach us.
A mind that has made the leap to universality gets smarter by coming up with ever-better explanations. This is the true intelligence explosion: universal explainers can in principle solve any problem that doesn’t violate the laws of physics. If an AGI has hard-wired instincts that are in conflict with its best moral explanations, it will be able to creatively route around or even reprogram itself, in exactly the same way that humans do.
So that makes me more optimistic about the ‘first contact’ scenario.
On the other hand, I’m much less sanguine about this than the critical rationalist camp (followers of Popper and Deutsch). Even with no further jumps beyond universality, the ability to think at a fraction of the speed of light really might make AGI a categorically different kind of being, which poses a far greater threat or opportunity than any human child would.
The other way in which I come apart from the crit rats is that I’m much more willing to invoke the precautionary principle, which is a dirty word for Deutsch.
I can’t prove that AGI would threaten human existence, and accelerationists can’t prove that it would boost us on our journey to utopia. But based on the existence of ‘misaligned’ humans, and the vast ocean of suffering that we creative problem-solvers have imposed on other intelligent species, I think it’s totally reasonable to be cautious this one time. As Taleb would say, the risk of ruin must be avoided at all cost.
And so I think my ideal outcome would be that we get incredibly capable AI tools—even if it creates lots of new and scary problems—but that we fail to actually create a successor species. At least for now.
On balance, I’ve probably shifted slightly closer to the doomer camp than I was before I wrote this post, even though I got more confident in some specific claims.
Here’s where I’m at, in handy-dandy table form:
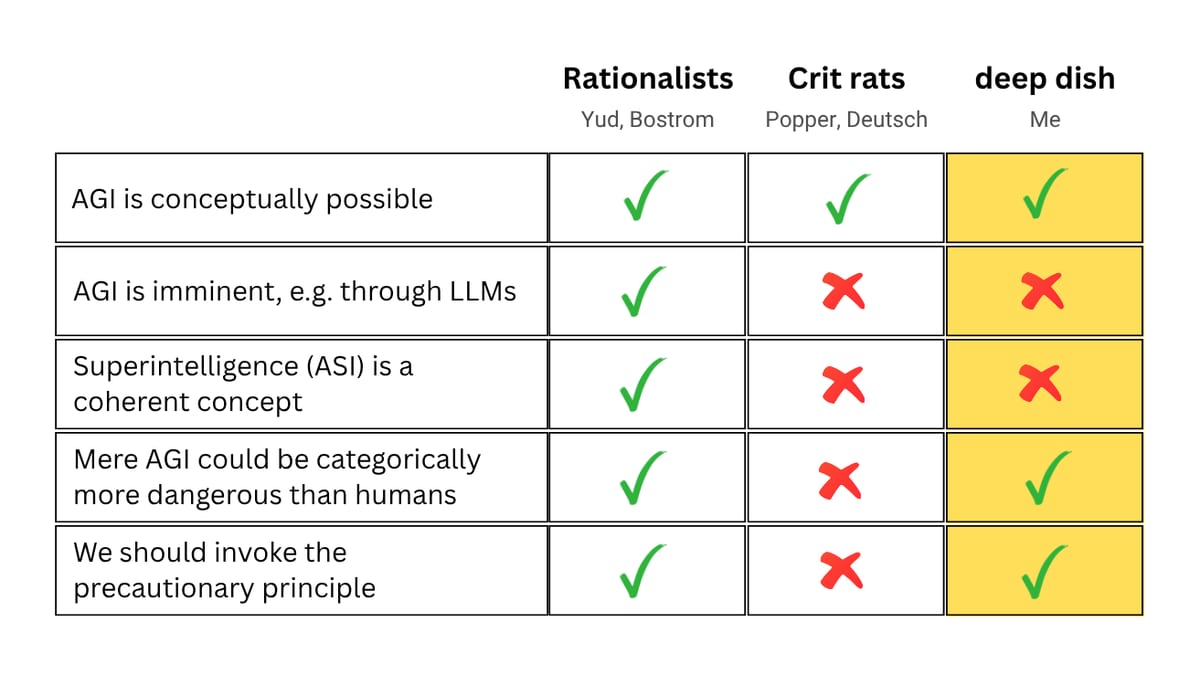
Thanks again to everyone for weighing in. I would of course appreciate any further thoughts.
NOW FOR SOMETHING COMPLETELY DIFFERENT
Book club is going great! Most recently we had Nicole (@elocinationn) on to talk about one of her faves, Jonathan Safran Foer’s Everything is Illuminated.
Listen on Spotify | Apple Podcasts
We’re also experimenting with YouTube, so you can check out the video here:
(And more book club discussions here.)



